Path-minimizing Latent ODEs for improved extrapolation and inference
Abstract
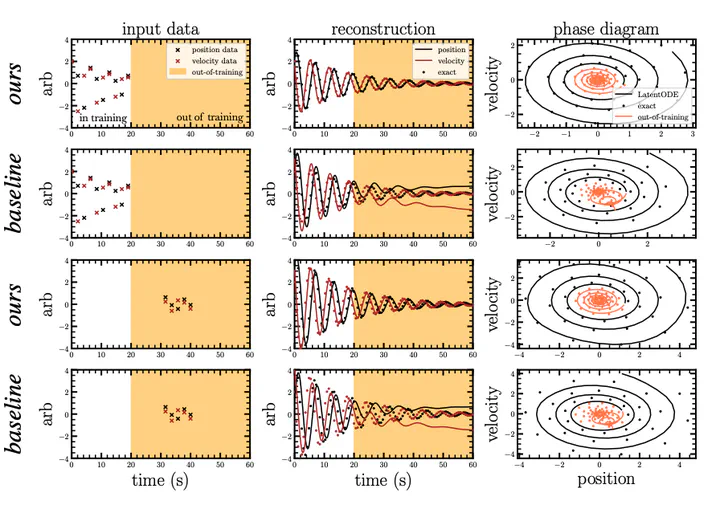
Latent ODE models provide flexible descriptions of dynamic systems, but they can struggle with extrapolation and predicting complicated non-linear dynamics. The latent ODE approach implicitly relies on encoders to identify unknown system parameters and initial conditions, whereas the evaluation times are known and directly provided to the ODE solver. This dichotomy can be exploited by encouraging time-independent latent representations. By replacing the common variational penalty in latent space with an ℓ2 penalty on the path length of each system, the models learn data representations that can easily be distinguished from those of systems with different configurations. This results in faster training, smaller models, more accurate interpolation and long-time extrapolation compared to the baseline ODE models with GRU, RNN, and LSTM encoder/decoders on tests with damped harmonic oscillator, self-gravitating fluid, and predator-prey systems. We also demonstrate superior results for simulation-based inference of the Lotka-Volterra parameters and initial conditions by using the latents as data summaries for a conditional normalizing flow. Our change to the training loss is agnostic to the specific recognition network used by the decoder and can therefore easily be adopted by other latent ODE models.
Type
Publication
MLST (full version) NeurIPS Workshop for Physical Sciences
ML Sampson, P Melchior (2024)
Latent ODE models provide flexible descriptions of dynamic systems, but they can struggle with extrapolation and predicting complicated non-linear dynamics. The latent ODE approach implicitly relies on encoders to identify unknown system parameters and initial conditions, whereas the evaluation times are known and directly provided to the ODE solver. This dichotomy can be exploited by encouraging time-independent latent representations. By replacing the common variational penalty in latent space with an ℓ2 penalty on the path length of each system, the models learn data representations that can easily be distinguished from those of systems with different configurations. This results in faster training, smaller models, more accurate interpolation and long-time extrapolation compared to the baseline ODE models with GRU, RNN, and LSTM encoder/decoders on tests with damped harmonic oscillator, self-gravitating fluid, and predator-prey systems. We also demonstrate superior results for simulation-based inference of the Lotka-Volterra parameters and initial conditions by using the latents as data summaries for a conditional normalizing flow. Our change to the training loss is agnostic to the specific recognition network used by the decoder and can therefore easily be adopted by other latent ODE models.